Reddit v zameno za trening umetne inteligence prejme 130 milijonov dolarjev
Slo-Tech - Znano je, koliko Reddit zasluži z licenciranjem svojih vsebin podjetjem, ki razvijajo umetno inteligenco. Potem ko so sredi leta 2023 napovedali novo politiko uporabe in sklenili pogodbi z Googlom in OpenAI, so lani prihodki iz tega sodelovanja dosegli 10 odstotkov vseh prihodkov podjetja.
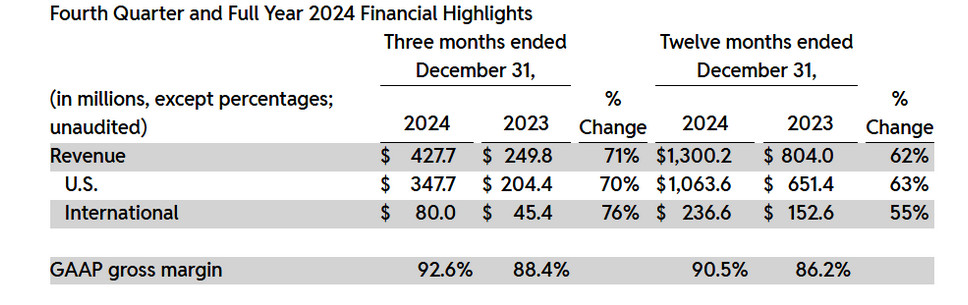
Google je plačal okrog 60 milijonov dolarjev, OpenAI pa približno 70 milijonov dolarjev. To so ocene iz dostopnih podatkov in izjav podjetja Reddit. Direktor operacij v Redditu Jen Wong je dejal, da sta omenjeni pogodbi vredni 10 odstotkov prihodkov podjetja, ki so lani znašali 1,3 milijarde dolarjev. Ta se povečuje in je v minulem četrtletju zrasel za 71 odstotkov medletno.
Ob tem Reddit poudarja, da pogodbe o uporabi vsebin za trening umetne inteligence sklepajo le s podjetji, ki pristanejo na določene pogoje, ki so izjemno pomembni za Reddit. Podrobnosti ni razkril, gre pa za zaščito zasebnosti oziroma anonimnost ter vpliv na Reddit.
Še vedno pa Reddit levji delež prihodkov ustvari z...
Google je plačal okrog 60 milijonov dolarjev, OpenAI pa približno 70 milijonov dolarjev. To so ocene iz dostopnih podatkov in izjav podjetja Reddit. Direktor operacij v Redditu Jen Wong je dejal, da sta omenjeni pogodbi vredni 10 odstotkov prihodkov podjetja, ki so lani znašali 1,3 milijarde dolarjev. Ta se povečuje in je v minulem četrtletju zrasel za 71 odstotkov medletno.
Ob tem Reddit poudarja, da pogodbe o uporabi vsebin za trening umetne inteligence sklepajo le s podjetji, ki pristanejo na določene pogoje, ki so izjemno pomembni za Reddit. Podrobnosti ni razkril, gre pa za zaščito zasebnosti oziroma anonimnost ter vpliv na Reddit.
Še vedno pa Reddit levji delež prihodkov ustvari z...



