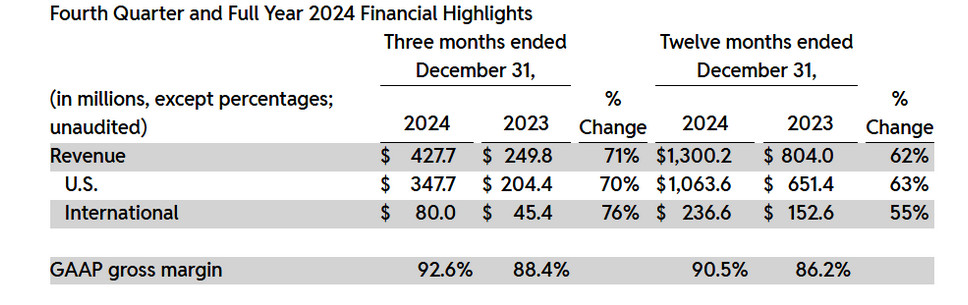
Anthropic izdal Claude 3.7
Slo-Tech - Iz Anthropica je prispel novi model umetne inteligence Claude 3.7, ki zmore delovati v dveh načinih. Odzivi so lahko klasični ali pa razmišljujoči (reasoning), s čimer lahko rešuje tudi težje zagonetke. Zaradi tega je hibridni model enostavneje uporabljati, zlasi kadar potrebujemo kombinirane odzive. Uporabnik (ki uporablja API) ima nadzor nad njegovim obnašanjem, na primer kako dolgo razmišlja in koliko računske moči troši. Hkrati model izpisuje (scratchpad), kako razmišlja oziroma rešuje problem. To je koristna informacija tudi za uporabnika, ki lahko vidi, ali bi se model bolje odrezal, če bi imel na voljo več časa, in podobno.
Claude 3.7 je precej boljši pri pisanju kode in razvoju, dobil pa je tudi orodje Claude Code za pisanje kode. Inženirji mu lahko delegirajo različna opravila, ki jih morajo rešiti pri programiranju. Razmišljujoči model je dobil dodatni trening na področjih pisanja kode, uporabe računalnikov, odgovarjanja na pravne dileme in podobne naloge, ki jih lahko...
Claude 3.7 je precej boljši pri pisanju kode in razvoju, dobil pa je tudi orodje Claude Code za pisanje kode. Inženirji mu lahko delegirajo različna opravila, ki jih morajo rešiti pri programiranju. Razmišljujoči model je dobil dodatni trening na področjih pisanja kode, uporabe računalnikov, odgovarjanja na pravne dileme in podobne naloge, ki jih lahko...